AI/Computer Vision
[논문 리뷰] Segment Anything
- -
본 논문은 4월 5일 Meta AI에서 발표되었습니다. 이름 그대로 어떤 것이든 segment를 해냅니다.(zero-shot)
paper link는 각각 arxiv와 segment anything 블로그에 1개씩 있는데 내용은 동일한 것 같습니다.
온라인에서 demo를 사용하실 분은 여기를 참고하시고 PPT로 따로 만든 자료는 여기를 참고 바랍니다.
논문 들어가기에 앞서 prompt(프롬프트)라는 용어를 알아야 합니다.
prompt : 사용자의 입력을 받는 것
정도로 해석하면 될 것 같습니다. 우리가 명령 프롬프트 창에서 직접 명령어를 주는 것처럼 말입니다.
Abstract
약 1100만 여개의 이미지에서 약 10억 개 이상의 마스크를 사용했습니다.
해당 이미지와 마스크는 (여기)에 공개되어 있습니다.
해당 모델이 zero-shot 성능이 좋다고 언급하고 있습니다.
1. Introduction
pretrain된 LLM(Large Language Model)은 zero-shot과 few-shot을 바탕으로 NLP에 큰 영향을 주고 있습니다.
컴퓨터 비전에서도 연구되었으나 그 정도는 상대적으로 미미하다고 판단됩니다.
이 연구를 통해 빠르고 강력하면서 일반화된 image segmentation 작업을 하고자 합니다.
이 목표의 달성을 위해서는 다음 3가지 질문을 해결해야 합니다.
- 제로샷 일반화를 가능하게 하는 작업은 무엇입니까? (What task will enable zero-shot generalization?)
- 해당 모델 아키텍처는 무엇입니까? (What is the corresponding model architecture?)
- 어떤 데이터가 이 작업과 모델링에 도움이 될 수 있습니까? (What data can power this task and model?)
└ Task

NLP에서 "prompt" 기술을 사용한 것에서 영감을 얻어 여기서 사용합니다. 프롬프트는 단순히
이미지에서 분할할 대상을 지정(이미지를 그림판에서 열고 object에 점 하나 찍는 것으로 생각)하는 것을 말합니다.
└ Model
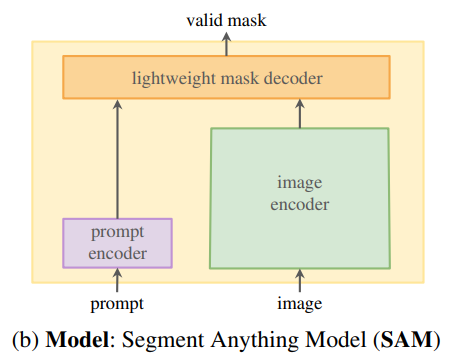
SAM(Segment Anything Model) = image encoder + prompt encoder + mask decoder
- 위처럼 각각 3개로 분리되면서 이미지 임베딩을 다른 프롬프트에서 재사용할 수 있습니다.
- 웹 브라우저에서 프롬프트 마스크를 50ms 이내에 측정 가능합니다.
- object의 Ambiguity(=모호성, e.g. object 중복. 애매한 prompt)을 인식하고 처리하기 위해 단일 프롬프트로 여러 마스크를 예측하도록 설계했습니다.
└ Data engine

3단계로 이루어져 있습니다.
- Assited-manual stage : 사람이 SAM(Segment Anything Model) 기반의 tool을 제공받아 그것으로 point를 찍으면 SAM이 그것을 기반으로 마스크를 어느 정도 만듭니다. 이 방식을 반복하여 labeling합니다. 정리하자면 SAM이 open segmentation dataset을 학습한 후 추론한 결과물을 사람에게 제공합니다.(이것은 당연히 완벽한 mask는 아니고)이 결과물을 사람이 이미지 내의 object들을 픽셀 단위급으로 수정합니다. 그리고 중간마다 수집된 데이터를 기반으로 주기적인 재학습을 거쳤습니다.(6번)
- Semi-automatic stage : 1단계에서 수집한 결과물로 SAM이 학습을 하고 추론을 한 결과물을 사람에게 제공합니다. 이미지 내의 object 중 SAM이 찾지 못하고 제외된 object들을 사람이 수정하여 처리합니다. 1단계와 마찬가지로 중간중간 주기적인 재학습을 거쳤습니다.(5번)
- Fully automatic stage : (완전 자동)SAM이 이미지에 32×32의 규칙적인 grid point를 주고 각 point에 대해 유효한 mask를 예측합니다.
└ Dataset

우리가 만든 것이 기존에 존재하던 다른 데이터셋보다 많은 마스크를 가지고 있습니다.
새로운 기초 모델의 초석이 되는 데이터셋이 되길 바랍니다.
└ Reponsible AI
SA-1B의 이미지는 지리적&경제적으로 다양한 국가 및 다양한 사람에게서 얻었습니다.(데이터셋의 공평성에 대한 해명을 나타낸 것 같습니다.) + 이 데이터셋은 (여기)에 있습니다.
└ Experiments
23개의 분할 데이터셋의 다양하고 새로운 제품으로 SAM이 종종 수동 주석 처리된 것보다 더 좋은 품질의 마스크를 생성하였습니다. edge detection, object proposal generation, instance segmentation과 같은 분야에도 효과적인 결과를 낼 수 있습니다. 물론 모델은 아직 개선의 여지가 남아있습니다.
└ Release
SA-1B 데이터셋은 연구 목적으로 릴리즈되었고 SAM은 허용 가능한 라이센스(Apache 2.0)입니다.
SAM은 온라인 데모로도 사용 가능합니다.(https://segment-anything.com/demo)
2. Segment Anything Task

NLP의 프롬프트에서 아이디어를 얻었습니다. 여기서 사용할 프롬프트는 foreground/background point, lough box.
mask와 같은 일반적으로 이미지에서 분할할 수 있는 것들 중 가질 수 있습니다.
프롬프트 분할 작업은 프롬프트가 지정된 '유효한' 분할 마스크를 반환하는 것입니다. 이 때, '유효한' 마스크의 요구사항은
프롬프트가 모호하고 여러 object를 참조할 수 있는 경우(Figure 3)에도 output이 해당 object 중 최소 하나에 대해 합리적인 마스크여야 합니다.
3. Segment Anything Model

- image encoder : 이미지당 한 번 실행되며 모델에 프롬프트를 표시하기 전에 적용할 수 있습니다.
- prompt encoder : 2개의 프롬프트 세트를 고려합니다.(①sparse(points, boxes, text) ②dense(masks)) 텍스트 인코더를 사용하여 각 프롬프트 유형에 대해 학습된 임베딩과 positinal 임베딩으로 point와 box를 나타냅니다.
- mask decoder : 이미지 임베딩, 프롬프트 임베딩 및 출력 토큰을 마스크에 효율적으로 매핑합니다.
- resolving ambiguity : 하나의 output으로 모델이 모호한 프롬프트가 제공되는 경우에 대비하여 단일 프롬프트에 대해 여러 output 마스크를 예측하도로 모델을 수정합니다. 마스크 순위는 IoU로 추정합니다. 그리고 마스크 결과들이 여러 개가 나올 수 있는데 논문 상에서는 3개의 마스크 출력으로 대부분의 일반적인 경우에 해결할 수 있다고 판단했습니다. 결과적으로 마스크 후보군은 3개를 가지면서 학습하게 됩니다.
- effficiency : CPU에서 최대 50ms 속도로 실행됩니다.
- losses and training : focal loss와 dice loss를 linear combination하여 마스크를 예측합니다.
4. Segment Anything Data Engine
이전의 1. Introduction - Data engine 설명한 내용과 동일하므로 생략하겠습니다.
5. Segment Anything Dataset
└ Image
사진 작가와 직접 작업하는 공급업체로부터 1,100만 개의 이미지셋을 받았습니다.
이 이미지셋은 고해상도(평균 3300×4950)로 데이터 크기로 인해 접근성과 저장 문제가 나타날 수 있습니다.
그래서 shortest side 부분을 1500 pixel로 다운샘플링하여 공개했습니다.(그럼에도 COCO 데이터셋(480×640)같은 일반적인 데이터셋보다는 훨씬 큽니다.)
└ Masks
자체적인 데이터 엔진을 통해서 11억 개의 마스크를 생산했고 99.1%는 완전 자동으로 생성되었습니다.
SA-1B는 자동으로 생성된 마스크만 포함되어 있습니다.
└ Mask quality
마스크 품질 추정을 위해 500개의 무작위 샘플링 이미지를 annotator들에게 품질 향상을 요청했습니다.
annotator들은 편집 도구의 브러쉬와 지우기를 사용해서 개선했습니다. 이렇게 annotator들이 만든 마스크 pair들의 IoU를 계산했고 94%의 pair가 90% 이상의 IoU를 가지고 있었습니다. 이를 통해 annotator와의 비교나 혹은 이전 연구에 비해서도 상대적으로 높은 품질을 가진다고 확인했습니다.
└ Mask properties

object를 어떻게 찍느냐에 따라 피사체 위치가 달라지기 때문에 위와 같이 데이터셋마다의 분포 차이가 발생하는 것으로 추정됩니다.(개인 각주 : 데이터셋마다의 편향이 있는 것일까요?)

SA-1B는 기존의 가장 큰 분할 데이터셋인 Open Images보다 11배 많은 이미지와 400배 많은 마스크를 가지고 있습니다.
6. Segment Anything RAI Analysis
수집한 데이터셋의 공정성, 형평성 문제를 언급하고 있는데 따로 다루지는 않겠습니다.
본 내용은 해당 paper의 7~8페이지에서 다루고 있습니다.
이후부터는 zero-shot에 관한 얘기인데 필요하다고 생각되면 추후에 내용을 추가하겠습니다.
결론적으로
- zero-shot을 가능하게 합니다.(처음 본 데이터도 prediction)
- segmentation 분야에서 추후 진행될 연구에 신뢰성을 줄 수 있는 데이터셋(SA-1B)을 구축했습니다.
여기에 tutorial notebook도 깔끔하게 잘 되어 있습니다. automatic한 방식은 automatic_mask_generator_example.ipynb, prompt한 방식은 predictor_example.ipynb, onnx를 export하는 방법은 onnx_model_example.ipynb에 나와있습니다. 다만 쓴 시점 기준으로 point, box가 아닌 text를 prompt로 받는 것은 공개가 아직 안된 것인지 확인되지 않습니다.
SAM을 가볍고 빠르게 이해하려면 포스팅을, 자세히 본다면 논문을, 바로 코드를 써야 한다면 깃허브를, 데모가 필요하면 여기를 참고하세요,
논문 자체가 데이터(mask)를 어떻게 만들어내고 그것의 품질과 공정성, 형평성을 어떻게 따질지에 대한 설명이 꽤 많이 들어가 있습니다. 개인적으로 바로 쓰기도 쉽고 성능도 놀라울 정도였습니다.
Reference
'AI > Computer Vision' 카테고리의 다른 글
| Segment Anything으로 labeling 없는 데이터를 fine tuning하기 (1) | 2023.06.22 |
|---|---|
| [PPT] Segment Anything (0) | 2023.06.19 |
| Segment Anything 사용법(demo) (0) | 2023.05.02 |
| IoU와 Dice Coefficient (0) | 2023.03.15 |
| [논문 리뷰] C-CAM: Causal CAM for Weakly Supervised Semantic Segmentation on Medical Image (0) | 2023.02.03 |
Contents
소중한 공감 감사합니다